Data Projects
I am also an avid programmer and a student of data science. I first became interested in Machine Learning techniques when I took part in the Erdos Institute Data Bootcamp in 2020. My team won first place out of twenty-six teams in the final-project competition at the end of the bootcamp.
I have encorporated many of these techniques in my research. More recently I have dived into the world of Deep Learning by exploring datasets and notebooks on Kaggle and have even tried my hand at competitions. Check out some of my projects below!
Sudoku Solver
Links: GitHub repository, App

- Created an application to solve a Sudoku puzzle correctly given its image as input.
- Wrote a custom pipeline which processes the image, identifies the filled digits using OCR and a neural network and produces a solution.
- Deployed a Docker containerized Dash/Plotly app to Google Cloud (GCP).
Bookend- guess the author
Links: GitHub repository
- Trained an ensemble classifier model on books scraped from project Gutenberg which can predict the authorship of a snippet of text with a 93% accuracy.
- Led a team of four and was responsible for dividing tasks and establishing a GitHub-based workflow to maximize productivity.
- Extracted text features and implemented a bag-of-words model which gave the highest prediction accuracy score (85%) among the models considered.
- Presented the results to judges from industry and others in a short video format.
- Team won first place among twenty-six teams at the Erdos Institute Data Science Bootcamp (2020).
BreweryXplorer- explore breweries in the US
Links: GitHub repository, Dashboard
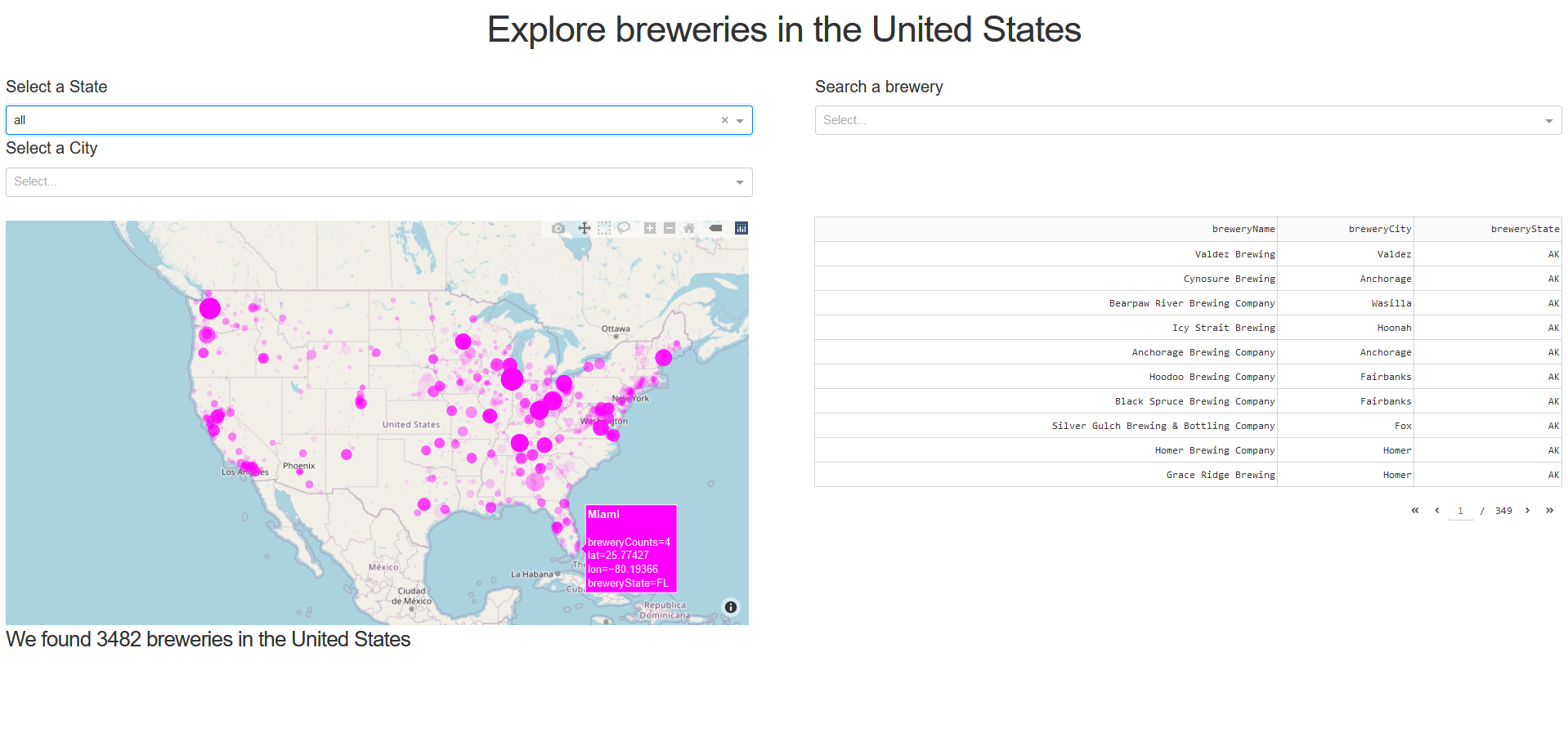
- Designed and deployed an interactive web app that lets users browse and search 3000+ breweries and pubs in the United States.
- Scraped and cleaned unstructured brewery data gathered from Wikipedia and other web sources.
- Designed an interactive Dashboard using Dash/Plotly which was deployed to Heroku.
IMDB movie reviews- good, bad or meh?
Links: Kaggle kernel
- The dataset from Kaggle contains 50,000 movie reviews labelled according to the sentiment.
- Trained a neural network to predict if a given movie review is “positive” or “negative”.
- Used a word2vec model trained on the reviews to generate semantic word embeddings which were used as features to a neural network.
- Model achieved 87% accuracy.
- This can be used for sentiment analysis of other text data such as restaurant reviews, tweets, news articles etc.